TIDL is TI’s software ecosystem for Deep learning algorithm (CNN) acceleration. TIDL allows users to run inference for pre-trained CNN/DNN models on TI Devices with C6x or C7x DSPs. In order to do this there are 3 steps.
In the previous weeks(7-8), we got the model training and development done(Step-1). It is now ready to be compiled(Step-2) and inferenced(Step-3) on BeagleBone AI-64.
Step-2: Model Compilation
The Model compilation is done on X86 - Linux(PC). It is done by Tidl importer tool. TIDL Translation (Import) tool can accept a pre-trained floating point model exported to tflite runtime. The user needs to run the model compilation (sub-graph(s) creation and quantization) on PC and then artifacts are generated. I faced a number of errors during this step. This is because BeagleBone AI-64 supports Tidl SDK Version 08_02_00_05, whereas the latest tidl sdk release is 10_00_04_00. Due to this, there were a lot of python compatibility issues. After researching a lot, interacting in forum to resolve errors, I finally ran the script to compile the model successfully.
If you are someone who wants to compile the model and is facing a alot of issues, I will soon do a PR in BeagleBone AI-64 docs and will add guide to compilation of custom models properly.
First of all, I build a docker image from the below Dockerfile:
My folder structure for model compilation. Here calibration files are used for quantization of model by compilation script.
.
├── cal_Data
│ ├── cal_1.npy
│ ├── cal_2.npy
│ ├── cal_3.npy
│ ├── cal_4.npy
│ ├── cal_5.npy
├── Model
│ ├──cnn_model.tflite
├── compile.py
├── config.json
├── edgeai-tidl-tools-08_02_00_05.Dockerfile
The mean and standard deviation relationship that is required for compilation process is as shown:
mean and std_dev relationship:
- range (0,255) mean = 0, std_dev = 1, scale = 1
- range (-1,1) mean = 127.5, std_dev = 127.5, scale = 1 / 127.5 = 0.0078431373
- range (0,1) mean = 0, std_dev = 255, scale = 1 / 255 = 0.0039215686
In my case the range of input to model is (0, 1). So the mean is 0 and std_dev is 0.0039215686 Then run the compilation script which I modified for my model with the command:
python3 compile.py -c config.json
—————————————————————————————————————————————————-
- Implementation
# origin: https://github.com/TexasInstruments/edgeai-tidl-tools/blob/master/examples/osrt_python/tfl/tflrt_delegate.py
import yaml
import json
import shutil
import os
import argparse
import tflite_runtime.interpreter as tflite
import numpy as np
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--config", help="Config JSON path", required=True)
parser.add_argument("-d", "--debug_level", default=0, help="Debug Level: 0 - no debug, 1 - rt debug prints, >=2 - increasing levels of debug and trace dump", required=False)
args = parser.parse_args()
os.environ["TIDL_RT_PERFSTATS"] = "1"
with open(args.config) as f:
config = json.load(f)
required_options = {
"tidl_tools_path": os.environ["TIDL_TOOLS_PATH"],
"artifacts_folder": "artifacts",
}
optional_options = {
"platform": "J7",
"version": " 7.2",
"tensor_bits": 8,
"debug_level": args.debug_level,
"max_num_subgraphs": 16,
"deny_list": "",
"accuracy_level": 1,
"advanced_options:calibration_frames": 2,
"advanced_options:calibration_iterations": 5,
"advanced_options:output_feature_16bit_names_list": "",
"advanced_options:params_16bit_names_list": "",
"advanced_options:quantization_scale_type": 0,
"advanced_options:high_resolution_optimization": 0,
"advanced_options:pre_batchnorm_fold": 1,
"ti_internal_nc_flag": 1601,
"advanced_options:activation_clipping": 1,
"advanced_options:weight_clipping": 1,
"advanced_options:bias_calibration": 1,
"advanced_options:add_data_convert_ops": 0,
"advanced_options:channel_wise_quantization": 0,
}
def gen_param_yaml(artifacts_folder_path, config):
layout = "NCHW" if config.get("data_layout") == "NCHW" else "NHWC"
model_file_name = os.path.basename(config["model_path"])
dict_file = {
"task_type": config["model_type"],
"target_device": "pc",
"session": {
"artifacts_folder": "",
"model_folder": "model",
"model_path": model_file_name,
"session_name": config["session_name"],
},
"postprocess": {
"data_layout": layout,
},
"preprocess": {
"data_layout": layout,
"mean": config["mean"],
"scale": config["scale"],
}
}
with open(os.path.join(artifacts_folder_path, "param.yaml"), "w") as file:
yaml.dump(dict_file, file)
if config["session_name"] in ["tflitert", "onnxrt"]:
shutil.copy(config["model_path"], os.path.join(artifacts_folder_path, model_file_name))
def infer_image(interpreter, image_files, config):
input_details = interpreter.get_input_details()
floating_model = input_details[0]['dtype'] == np.float32
batch = input_details[0]['shape'][0]
height = input_details[0]['shape'][1] # 150
width = input_details[0]['shape'][2] # 1152
# Initialize input_data array with the shape [batch, height, width]
input_data = np.zeros((batch, height, width), dtype=np.float32)
# Process calibration arrays
for i in range(batch):
img = np.load(image_files[i]) # Load numpy array directly
if img.shape != (height, width):
raise ValueError(f"Array {image_files[i]} has shape {img.shape}, expected ({height}, {width})")
input_data[i] = img
# Ensure input data type matches the model’s requirement
if not floating_model:
input_data = np.uint8(input_data)
config['mean'] = [0]
config['scale'] = [1]
interpreter.resize_tensor_input(input_details[0]['index'], [batch, height, width])
interpreter.allocate_tensors()
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
def compose_delegate_options(config):
delegate_options = {}
delegate_options.update(required_options)
delegate_options.update(optional_options)
if "artifacts_folder" in config:
delegate_options["artifacts_folder"] = config["artifacts_folder"]
if "tensor_bits" in config:
delegate_options["tensor_bits"] = config["tensor_bits"]
if "deny_list" in config:
delegate_options["deny_list"] = config["deny_list"]
if "calibration_iterations" in config:
delegate_options["advanced_options:calibration_iterations"] = config["calibration_iterations"]
delegate_options["advanced_options:calibration_frames"] = len(config["calibration_images"])
if config["model_type"] == "od":
delegate_options["object_detection:meta_layers_names_list"] = config["meta_layers_names_list"] if (
"meta_layers_names_list" in config) else ""
delegate_options["object_detection:meta_arch_type"] = config["meta_arch_type"] if (
"meta_arch_type" in config) else -1
if ("object_detection:confidence_threshold" in config and "object_detection:top_k" in config):
delegate_options["object_detection:confidence_threshold"] = config["object_detection:confidence_threshold"]
delegate_options["object_detection:top_k"] = config["object_detection:top_k"]
return delegate_options
def run_model(config):
print("\nRunning_Model : ", config["model_name"], "\n")
# set delegate options
delegate_options = compose_delegate_options(config)
# delete the contents of this folder
os.makedirs(delegate_options["artifacts_folder"], exist_ok=True)
for root, dirs, files in os.walk(delegate_options["artifacts_folder"], topdown=False):
[os.remove(os.path.join(root, f)) for f in files]
[os.rmdir(os.path.join(root, d)) for d in dirs]
calibration_images = config["calibration_images"]
numFrames = len(calibration_images)
# set interpreter
delegate = tflite.load_delegate(os.path.join(
delegate_options["tidl_tools_path"], "tidl_model_import_tflite.so"), delegate_options)
interpreter = tflite.Interpreter(
model_path=config["model_path"], experimental_delegates=[delegate])
# run interpreter
for i in range(numFrames):
start_index = i % len(calibration_images)
input_details = interpreter.get_input_details()
batch = input_details[0]["shape"][0]
input_images = []
# for batch > 1 input images will be more than one in single input tensor
for j in range(batch):
input_images.append(
calibration_images[(start_index+j) % len(calibration_images)])
infer_image(interpreter, input_images, config)
gen_param_yaml(delegate_options["artifacts_folder"], config)
print("\nCompleted_Model : ", config["model_name"], "\n")
run_model(config)
—————————————————————————————————————————————————-
After running the above script, the compiled artifacts got generated in the folder artifacts.
Structure of artifacts folder:
├── artifacts_folder
│ ├── 26_tidl_io_1.bin
│ ├── 26_tidl_net.bin
│ ├── allowedNode.txt
│ ├── cnn_model.tflite
│ ├── param.yaml
│ └── tempDir
│ ├── 26_calib_raw_data.bin
│ ├── 26_tidl_io_.perf_sim_config.txt
│ ├── 26_tidl_io_.qunat_stats_config.txt
│ ├── 26_tidl_io_1.bin
│ ├── 26_tidl_io__LayerPerChannelMean.bin
│ ├── 26_tidl_io__stats_tool_out.bin
│ ├── 26_tidl_net
│ │ ├── bufinfolog.csv
│ │ ├── bufinfolog.txt
│ │ └── perfSimInfo.bin
│ ├── 26_tidl_net.bin
│ ├── 26_tidl_net.bin.layer_info.txt
│ ├── 26_tidl_net.bin.svg
│ ├── 26_tidl_net.bin_netLog.txt
│ ├── 26_tidl_net.bin_paramDebug.csv
│ ├── graphvizInfo.txt
│ └── runtimes_visualization.svg
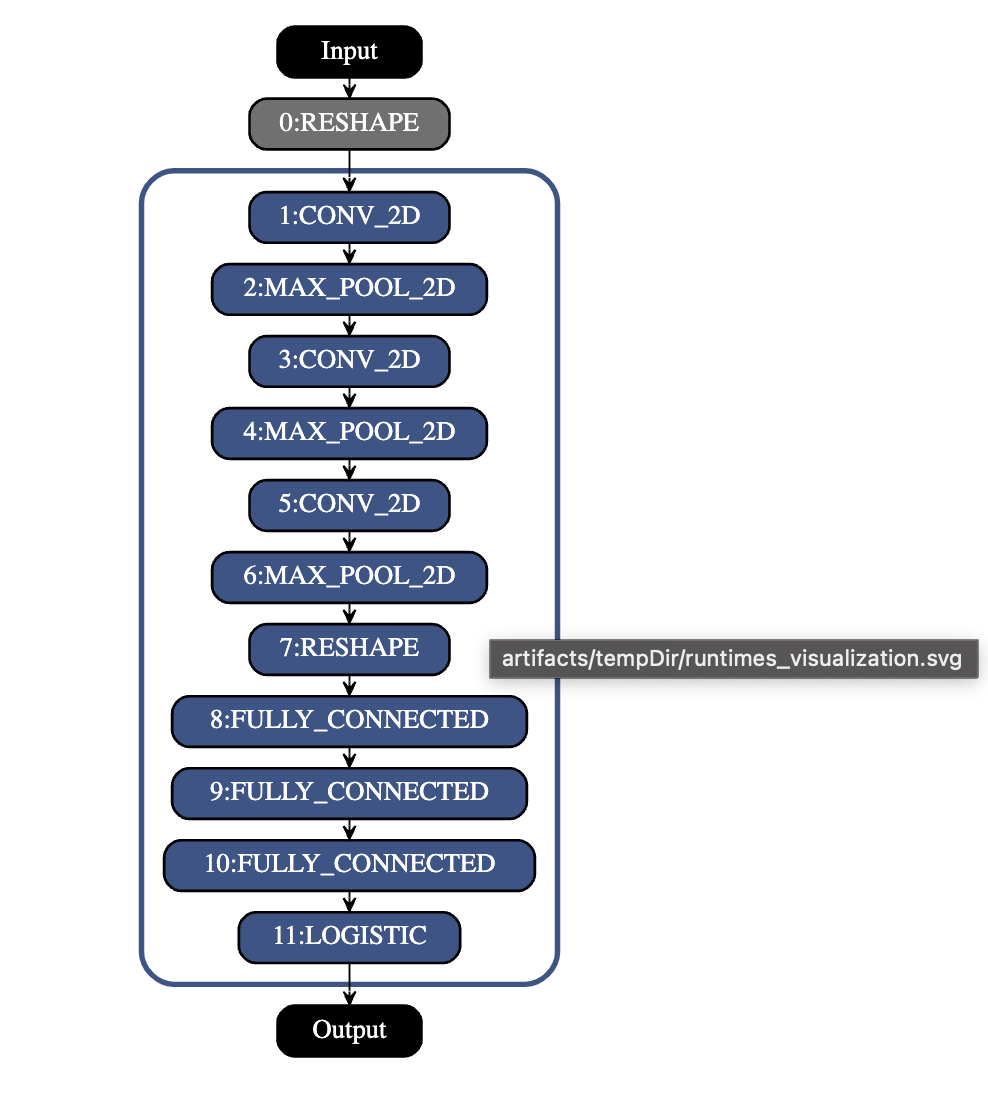
- The runtime_visualization.svg:
- 26_tidl_net.bin.svg
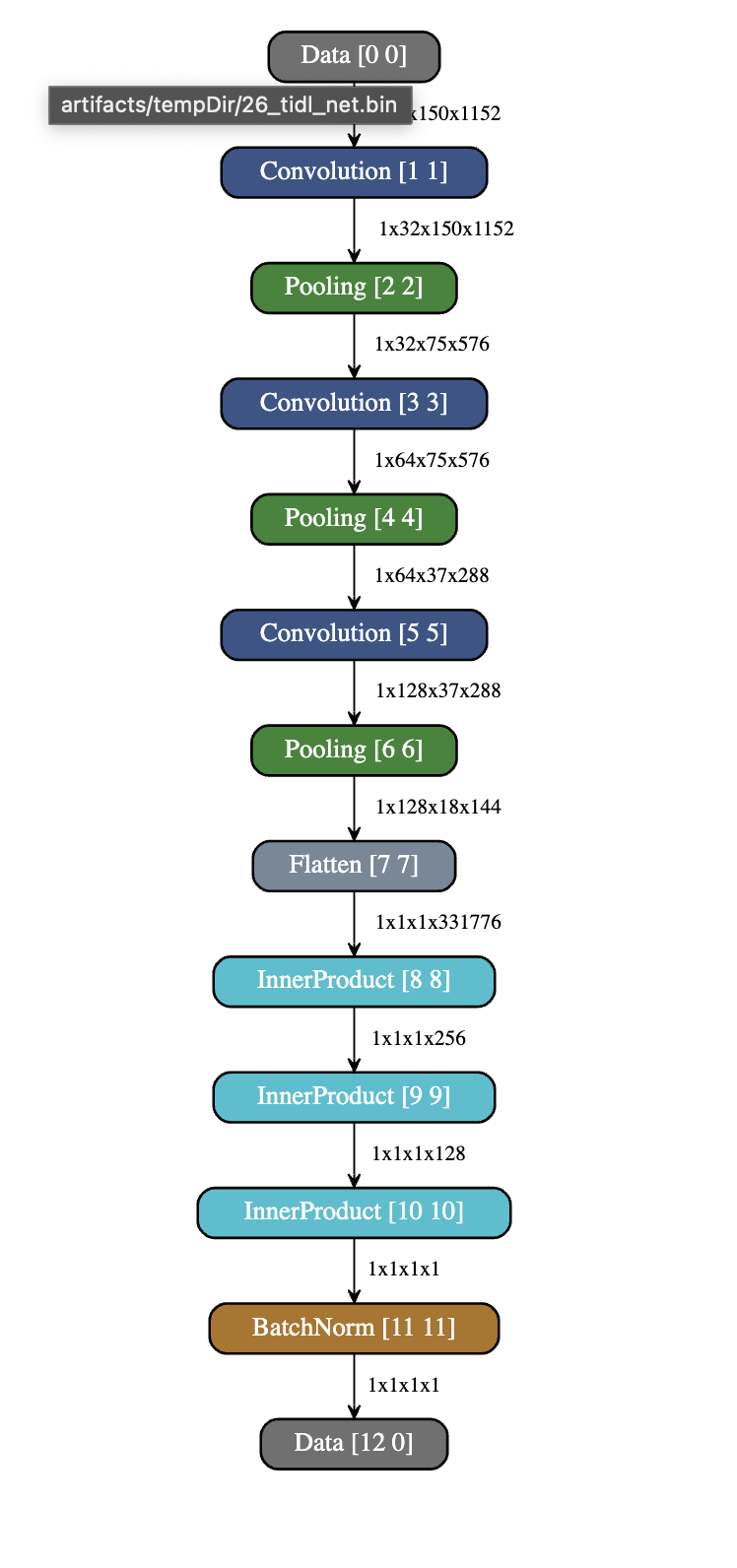
The above images shows that the compilation process was a success. Now, let’s move to inferencing(Step-3).
Step-3: Inferencing
The inferencing is done on ARM - Linux (TI SOC). BeagleBone AI-64 comes with TI SOC version 08_02_00_05. The generated artifacts are used for inferencing on the device. Now, I transferred the model, artifacts folder, etc., to the BeagleBone AI-64 via SSH.
Directory structure:
├── Model
│ └── cnn_model.tflite
├── artifacts
│ ├── 26_tidl_io_1.bin
│ ├── 26_tidl_net.bin
│ ├── allowedNode.txt
│ ├── cnn_model.tflite
│ ├── param.yaml
│ └── tempDir
│ ├── 26_calib_raw_data.bin
│ ├── 26_tidl_io_.perf_sim_config.txt
│ ├── 26_tidl_io_.qunat_stats_config.txt
│ ├── 26_tidl_io_1.bin
│ ├── 26_tidl_io__LayerPerChannelMean.bin
│ ├── 26_tidl_io__stats_tool_out.bin
│ ├── 26_tidl_net
│ │ ├── bufinfolog.csv
│ │ ├── bufinfolog.txt
│ │ └── perfSimInfo.bin
│ ├── 26_tidl_net.bin
│ ├── 26_tidl_net.bin.layer_info.txt
│ ├── 26_tidl_net.bin.svg
│ ├── 26_tidl_net.bin_netLog.txt
│ ├── 26_tidl_net.bin_paramDebug.csv
│ ├── graphvizInfo.txt
│ └── runtimes_visualization.svg
├── environment.yml
├── inferencing
│ └── tflite_model_inferencing.ipynb
└── test data
├── X_test.npy
└── y_test.npy
Before I was running onboard image. But, it’s size is only 8Gb which gave me memory overflowed error. So I flashed the bbai64-debian-11.8-xfce-edgeai-arm64-2023-10-07-10gb.img.xz image on a 32GB SD Card. After setting up the inferencing folder, 13GB remained available.
Then, I conducted inferencing using onboard CPUs and it worked fine.
After this I Attempted inferencing with the libtidl_tfl_delegate library.
Inferencing code:
import tensorflow as tf
tflite_model_path = '../Model/cnn_model.tflite'
delegate_lib_path = '/usr/lib/libtidl_tfl_delegate.so'
delegate_options = {
'artifacts_folder': '../artifacts_folder',
'tidl_tools_path': '/usr/lib/',
'import': 'no'
}
try:
print('1')
tidl_delegate = tf.lite.experimental.load_delegate(delegate_lib_path, delegate_options)
print(tidl_delegate)
except Exception as e:
print("An error occurred:", str(e))
if tidl_delegate:
print("I am inside")
interpreter = tf.lite.Interpreter(model_path=tflite_model_path, experimental_delegates=[tidl_delegate])
else:
print("I didn't go inside")
interpreter = tf.lite.Interpreter(model_path=tflite_model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print("Input details:", input_details)
print("Output details:", output_details)
Whenever I run the above code, the initialization with custom delegate gave kernel restarted pop-up. There was no error message just kernel restarted always. After figuring out a lot, it came out that the error was coming due to python and tflite_runtime version conflict. Now when I initialize the interpreter with custom delegate this is coming:
Number of subgraphs:1 , 11 nodes delegated out of 12 nodes
APP: Init ... !!!
MEM: Init ... !!!
MEM: Initialized DMA HEAP (fd=5) !!!
MEM: Init ... Done !!!
IPC: Init ... !!!
IPC: Init ... Done !!!
REMOTE_SERVICE: Init ... !!!
REMOTE_SERVICE: Init ... Done !!!
8803.328634 s: GTC Frequency = 200 MHz
APP: Init ... Done !!!
8803.328715 s: VX_ZONE_INIT:Enabled
8803.328724 s: VX_ZONE_ERROR:Enabled
8803.328733 s: VX_ZONE_WARNING:Enabled
8803.329329 s: VX_ZONE_INIT:[tivxInitLocal:130] Initialization Done !!!
8803.329407 s: VX_ZONE_INIT:[tivxHostInitLocal:86] Initialization Done for HOST !!!
It is stuck here and not moving forward.
From the remote-core logs(captured from /opt/vision_apps/vx_app_arm_remote_log.out), I got this error:-
C7x_1 ] 1243.288393 s: VX_ZONE_ERROR:[tivxAlgiVisionAllocMem:184] Failed to Allocate memory record 5 @ space = 17 and size = 170281740 !!!
I remained stuck with this error and it is not yet resolved. Hoping to resolve it soon.
In the next week, I will move to developing a pipeline for real-time inferencing.
I hope you found this blog insightful.
Thanks for reading the blog.
Happy Coding!!