The next thing in hand is to generate a real-time pipeline. In order to make a real-time pipeline, I would first need a input pipeline, that would extract audio and visual features from the frames and then process it in a format that is compatible to be fed into the model(150, 1152) for inference.
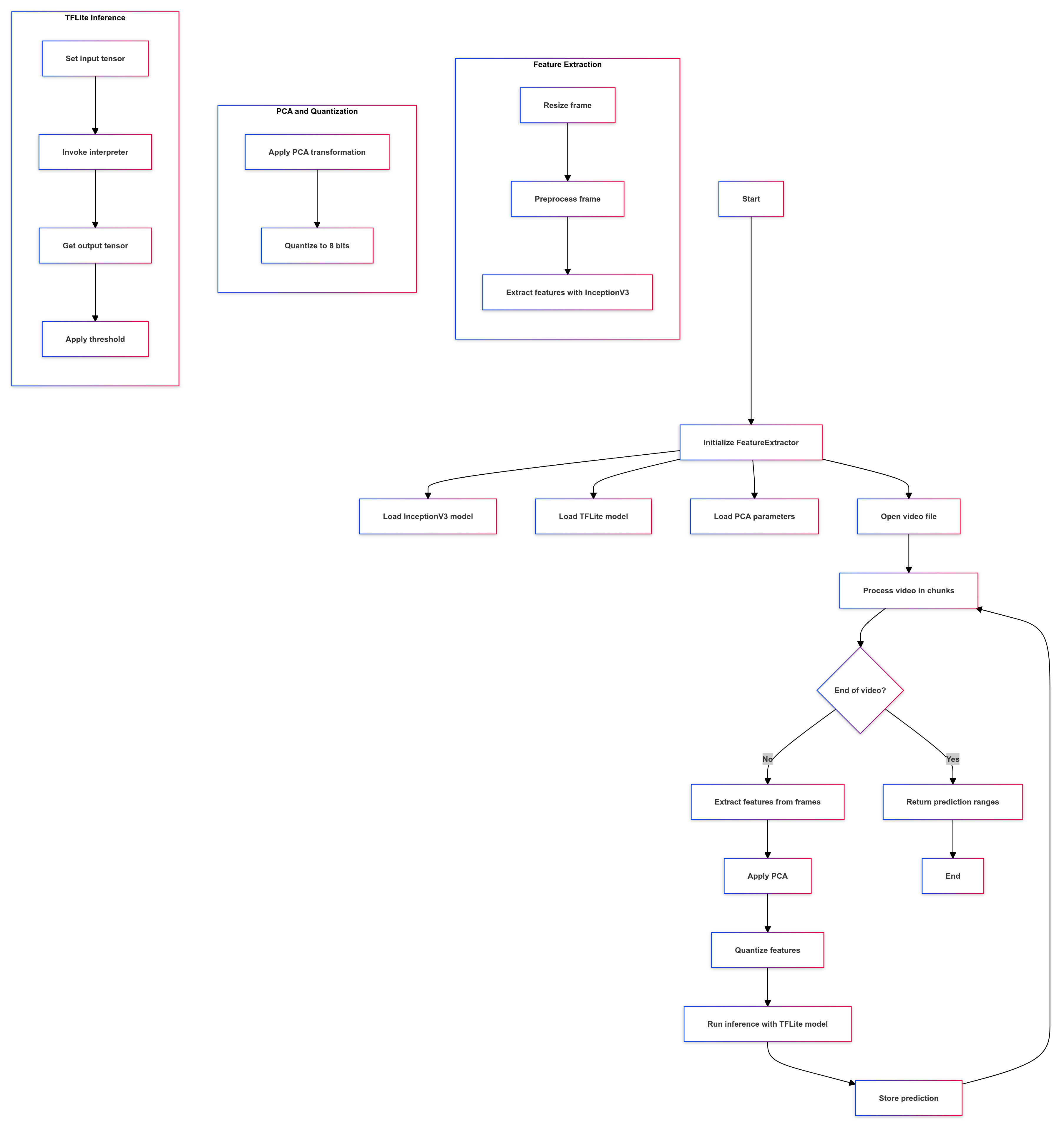
Details of Visual Features processing:
- Initialization: Loads an InceptionV3 model for feature extraction. Loads a TensorFlow Lite model for classification. Loads PCA (Principal Component Analysis) parameters.
- Feature Extraction: Extracts features from video frames using the InceptionV3 model.
- Video Processing: Processes the video in chunks of 150 frames. Extracts features from frames at regular intervals.
- Feature Processing: Applies PCA to reduce feature dimensionality. Quantizes the features to 8 bits.
- Classification: Uses the TensorFlow Lite model to classify the processed features. Returns prediction ranges (start frame, end frame, and predicted label).
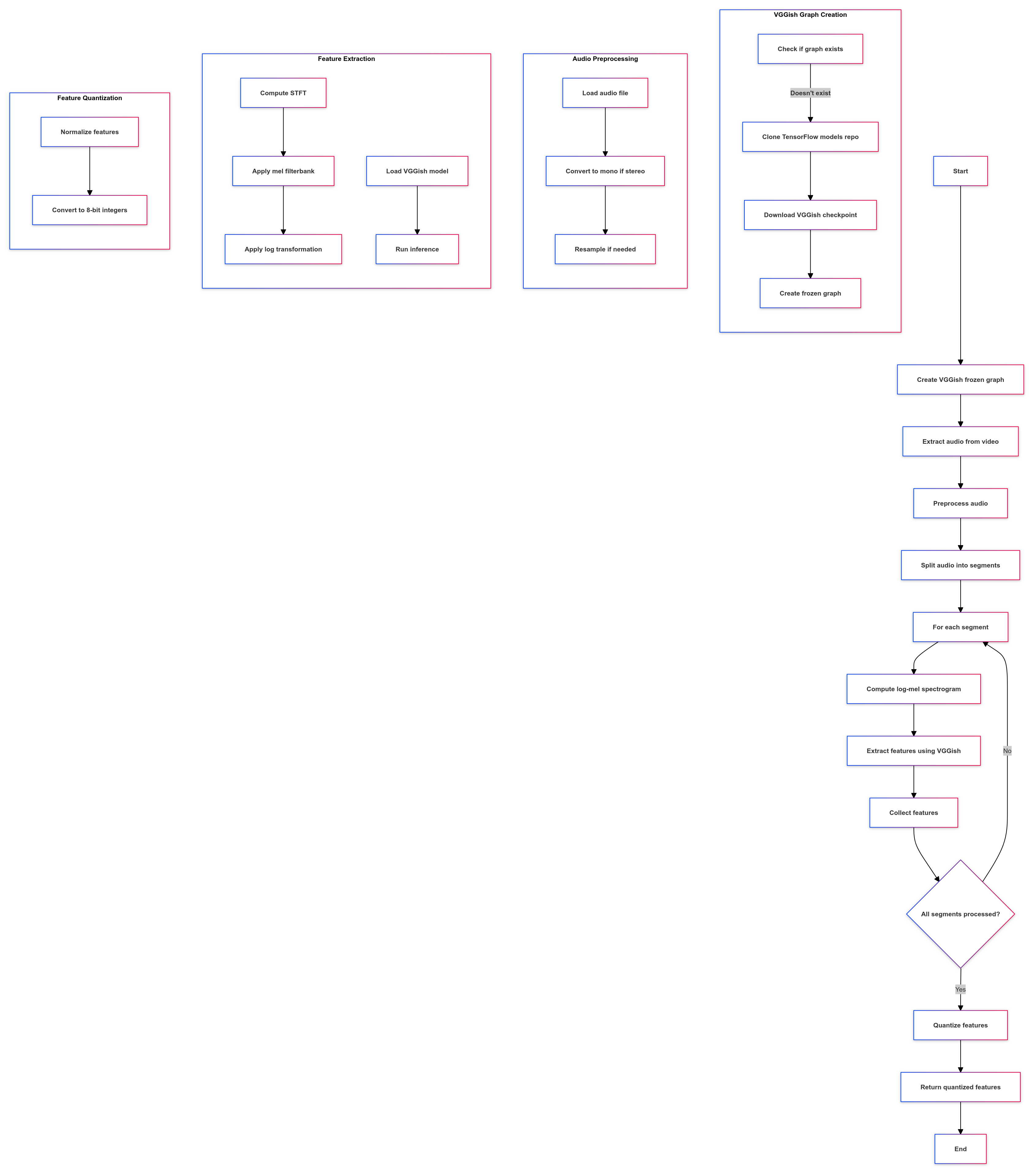
Details of Audio Features processing:
- Initialization and Setup: Imports necessary libraries. Defines paths for input video and output audio.
- VGGish Model Preparation: Creates a frozen graph of the VGGish model if it doesn’t exist.
- Audio Preprocessing: Extracts audio from the video. Preprocesses the audio (resampling, converting to mono if needed).
- Feature Extraction: Computes log-mel spectrogram from audio segments. Uses the VGGish model to extract features from the spectrogram.
- Post-processing: Quantizes the extracted features to 8-bit integers.
After this both of these features are merged and the features are now ready to be fed into the model.
Workflow:
The video is loaded from its file, and frames are recorded at intervals of 250ms (i.e., 4 frames per second). After collecting 150 frames (150/4 = 37.5 seconds), inference is performed. The result of the inference is stored in a tuple, which contains the label, start frame and end frame at the rate the video is loaded (not at 4 frames per second to avoid a flickery output video). After performing inference and storing the results for all video frames in chunks of 150 frames, the output video is displayed. When the label for a frame is 0 (non-commercial), the frame is displayed as it is. However, when the label for a frame is 1 (commercial), a black screen is shown instead.
Note
Initially, when I followed this workflow and started performing inference on videos, I realized that extracting audio features was taking significantly longer compared to visual features. For example, for a 30-second video, visual features were extracted in 30-35 seconds, but audio features took 5 minutes for the same. Therefore, I decided to exclude audio features, as the accuracy was similar with or without them. I trained a new CNN model using only visual features (shape: (150, 1024)). (1152-128 = 1024). The results below are based on that model.
Results:
I tested the complete pipeline on three videos. One was a random commercial video downloaded from YouTube, another was a non-commercial news video, and the last was a mix of commercial and non-commercial content (drama + commercial). (Small chunks of compressed videos are included with the results.)
Results on a random commercial-video:
- Video length: 150 seconds.
- Processing time: 151 seconds.
- Accuracy: 80%
Results on non-commercial video(news):
- Video length: 176 seconds.
- Processing time: 186 seconds
- Accuracy: 80%
Results on Mix Video(dramas+Commercial):
- Video length: 30 mins
- Processing time: 33-34 mins
- Accuracy: 65-70%
- Here, see how the transition at 1:20 happens when commercial gets over and drama get started.
Above video after post-processing:
(Sorry for the bad quality of videos, but I had to compress the videos to 2% of its original size so I could post it here)
There is a slight decrease in FPS, but it is barely noticeable.
I’m currently running this on my system and will be testing it on the BeagleBone AI-64 next.
This is not real-time pipeline as video is first processed and then displayed.
Real-time pipeline
—————————————————————————————————————————————————-
- Implementation
import argparse
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input
from tensorflow.keras.preprocessing import image
import time
import queue
import threading
q = queue.Queue()
predicted_label = queue.Queue()
label_event = threading.Event()
end_frame = 0
def extract_features_from_frame(frame, model):
img = cv2.resize(frame, (299, 299))
img = img[:, :, ::-1]
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
return features.flatten()
def load_pca(pca_mean_path, pca_eigenvals_path, pca_eigenvecs_path):
pca_mean = np.load(pca_mean_path)[:, 0]
pca_eigenvals = np.load(pca_eigenvals_path)[:1024, 0]
pca_eigenvecs = np.load(pca_eigenvecs_path).T[:, :1024]
return pca_mean, pca_eigenvals, pca_eigenvecs
def apply_pca(features, pca_mean, pca_eigenvals, pca_eigenvecs):
features = features - pca_mean
features = features.dot(pca_eigenvecs)
features /= np.sqrt(pca_eigenvals + 1e-4)
return features
def quantize_features(features, num_bits=8):
num_bins = 2 ** num_bits
min_val = np.min(features)
max_val = np.max(features)
bin_edges = np.linspace(min_val, max_val, num_bins + 1)
quantized = np.digitize(features, bin_edges[:-1])
quantized = np.clip(quantized, 0, num_bins - 1)
return quantized
def run_inference(interpreter, input_data):
interpreter.set_tensor(interpreter.get_input_details()[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(interpreter.get_output_details()[0]['index'])
return output_data
def evaluate_model(interpreter, X_test, threshold=0.5):
input_data = np.expand_dims(X_test[0], axis=0).astype(np.float32)
predicted_output = run_inference(interpreter, input_data)
predicted_label = (predicted_output >= threshold).astype(int)[0][0]
return predicted_label
def display_chunk_results(target_fps=40):
frame_delay = 1 / target_fps
prev_time = time.time()
frameCount = 0
flag = 0
global end_frame
end_frame1 = end_frame
while True:
if not label_event.is_set():
continue
if q.empty():
break
frameCount += 1
if flag == 0 or frameCount >= end_frame1:
current_label = predicted_label.get()
flag = 1
end_frame1 = end_frame
frame = q.get()
if current_label == 1:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame = cv2.cvtColor(frame, cv2.COLOR_GRAY2BGR)
frame[:, :] = 0
current_time = time.time()
elapsed_time = current_time - prev_time
sleep_time = frame_delay - elapsed_time
cv2.putText(frame, f'Label: {current_label}', (frame.shape[1] - 200, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Frame', frame)
if sleep_time > 0:
time.sleep(sleep_time)
prev_time = time.time()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
def process_video(args):
global predicted_label, end_frame
model = InceptionV3(weights='imagenet', include_top=False, pooling='avg')
interpreter = tf.lite.Interpreter(model_path=args.model_path)
interpreter.allocate_tensors()
pca_mean_path = './pca/mean.npy'
pca_eigenvals_path = './pca/eigenvals.npy'
pca_eigenvecs_path = './pca/eigenvecs.npy'
pca_mean, pca_eigenvals, pca_eigenvecs = load_pca(pca_mean_path, pca_eigenvals_path, pca_eigenvecs_path)
cap = cv2.VideoCapture(args.video_path)
chunk_size = 150
frame_count = 0
fps = cap.get(cv2.CAP_PROP_FPS)
interval_frames = int(fps * (250 / 1000))
while True:
frame_features_list = []
frames_in_chunk = 0
start_frame = frame_count
while frames_in_chunk < chunk_size:
ret, frame = cap.read()
if not ret:
break
q.put(frame)
# print(q.qsize())
if frame_count % interval_frames == 0:
features = extract_features_from_frame(frame, model)
frame_features_list.append(features)
frames_in_chunk += 1
frame_count += 1
if frames_in_chunk < chunk_size:
break
features = np.array(frame_features_list)
reduced_features = apply_pca(features, pca_mean, pca_eigenvals, pca_eigenvecs)
final_features = quantize_features(reduced_features)
final_features = final_features / 255
final_features = np.reshape(final_features, (1, 150, 1024))
predicted_label.put(evaluate_model(interpreter, final_features))
end_frame = frame_count - 1
label_event.set()
print(f"Inferencing on frames {start_frame} to {end_frame} done. Prediction: {predicted_label.queue[-1]}")
cap.release()
label_event.set()
def main():
parser = argparse.ArgumentParser(description='Process a video and classify frames.')
parser.add_argument('--model_path', type=str, required=True, help='Path to the TFLite model file')
parser.add_argument('--video_path', type=str, required=True, help='Path to the video file')
args = parser.parse_args()
thread = threading.Thread(target=process_video, args=(args,))
thread.start()
display_chunk_results()
thread.join()
if __name__ == "__main__":
main()
—————————————————————————————————————————————————-
-
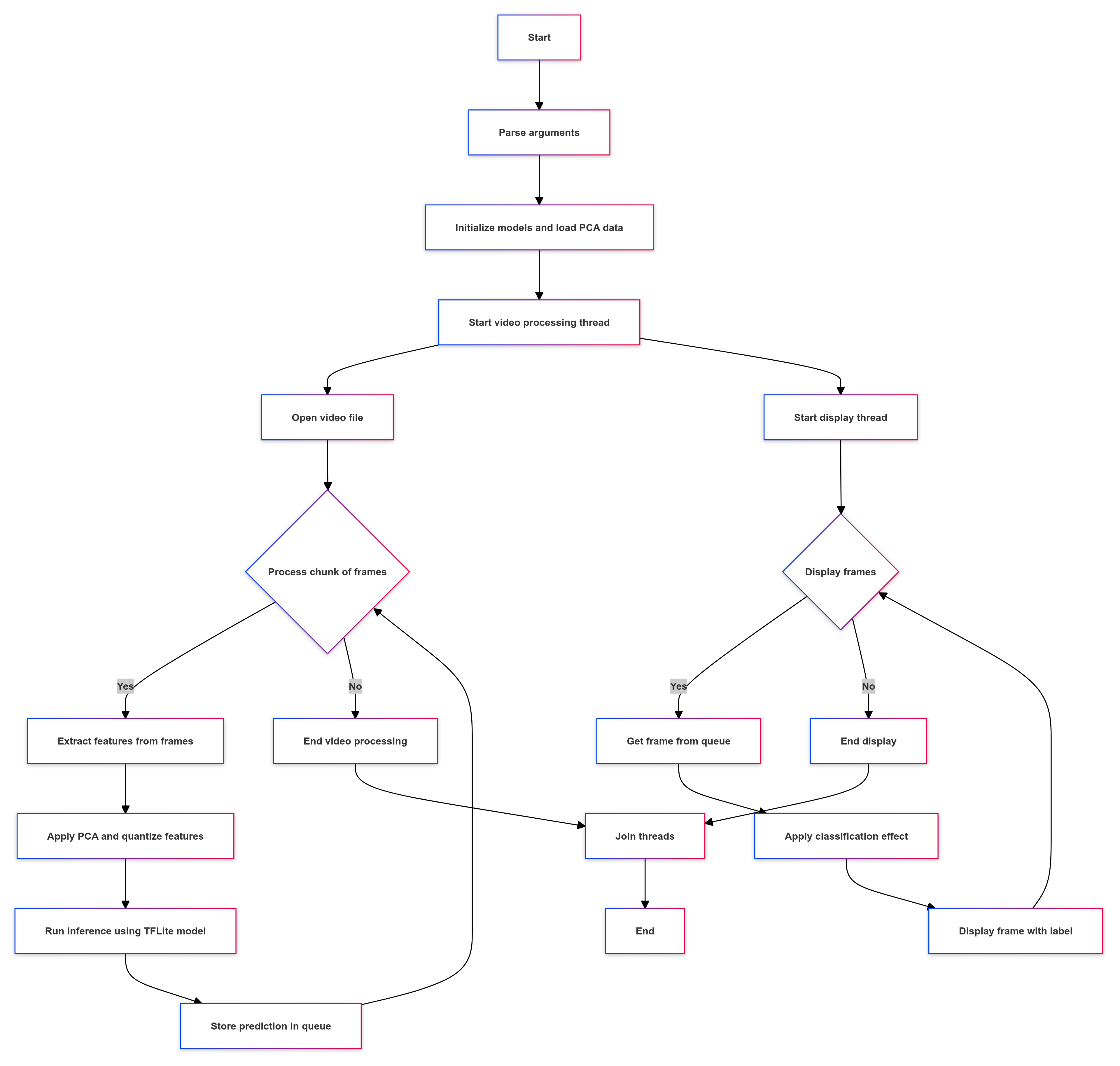
Workflow The pipeline consists of two threads. The main thread is responsible for display, while the processing thread captures input from the VideoCapture device and processes it. Frames are continuously added to a queue as they come in. Every second, four frames are selected at 250ms intervals. Once 150 frames have been collected at a rate of 4fps, inference is performed, and the results are displayed by the main thread using the frame queue. Meanwhile, the processing of the next set of frames occurs in the second thread simultaneously.
-
Results
Laptop: The pipeline is extremely fast, maintaining continuity. It takes 1 minute to process the initial chunk of frames. As soon as the display of the first chunk begins (at >35fps), processing of the next chunk starts concurrently. By the time the first chunk finishes displaying, the second chunk’s processing is complete, and the third chunk’s processing is already underway, ensuring continuous display.
BeagleBone AI-64: The results show significant improvement over the previous approach of processing the entire video before displaying it. The first chunk of frames is ready in 7 minutes. With the display set at 7fps, continuity is maintained, allowing smooth viewing after the initial 7 minutes without any lag.
About the error which I got last week. I have raised an issue for it in Ti e2e Forum. Link
Thanks for reading the blog.
Happy Coding!!