In this blog, I will be introducing edgeai and TIDL. So, let’s begin folks.
Edge AI
Edge AI refers to the deployment of AI applications locally on devices at the edge of the network, rather than in centralized data centers or cloud environments. This approach enables AI computations to be performed directly on devices like smartphones, cameras, drones, and IoT devices, allowing for faster data processing, reduced latency, and improved privacy.
Edge AI devices are better than sending data to the cloud for processing because they offer faster response times by handling computations locally, which is crucial for real-time applications like autonomous vehicles, industrial automation and commercial detection from live videos. They improve privacy and security by keeping sensitive data on the device, reduce bandwidth usage and associated costs, and provide reliable operation even without internet connectivity. Additionally, Edge AI enhances scalability and energy efficiency, making it ideal for large-scale deployments and battery-powered devices, while allowing for customization tailored to specific tasks and environments.
BeagleBone AI-64

The BeagleBone AI-64 is a single-board computer designed to enable artificial intelligence (AI) and machine learning (ML) applications on edge devices with accelerated inferencing. It is specifically engineered to handle AI workloads locally, making it a robust platform for Edge AI applications. I have discussed in detail how BeagleBone AI-64 plays a major role in this project in the blog GSoC - I made it!. In summary the C7x DSPs and MMA accelerator present in BeagleBone AI-64 increases performance and reduces the latency time during real-time inferencing.
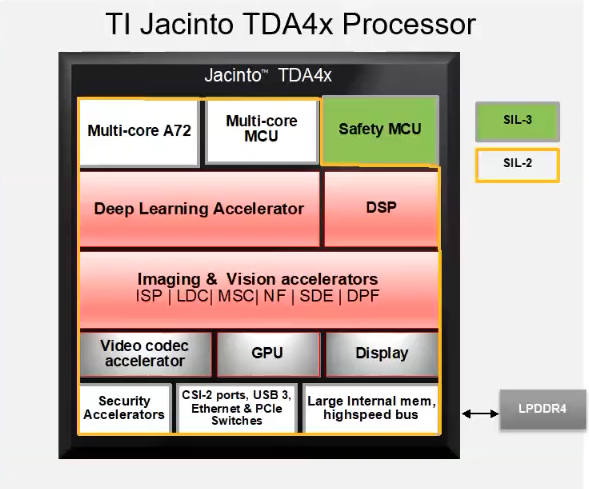
TIDL
TIDL (TI Deep Learning) is a software framework developed by Texas Instruments to optimize and accelerate deep learning inference on TI’s embedded processors. It supports model conversion from popular frameworks like TensorFlow, Caffe, and ONNX, and leverages hardware accelerators like DSPs and AI accelerators for efficient execution TIDL is designed for low power consumption and high performance, making it ideal for applications in consumer sectors where it enables the deployment of complex models for tasks like image classification, object detection etc.
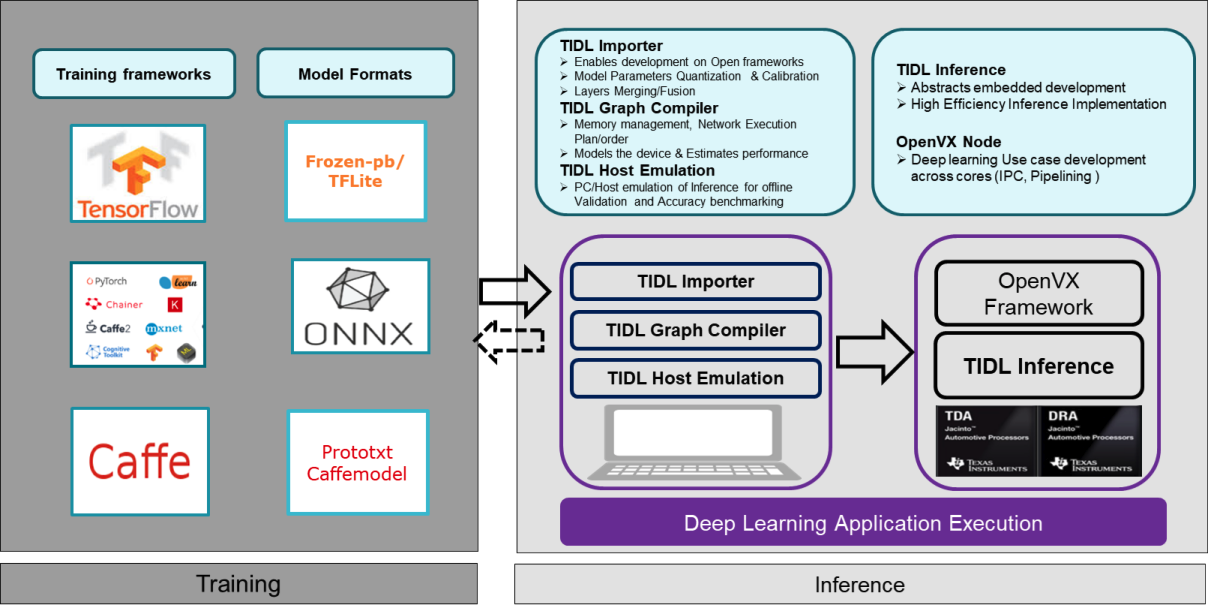
The BeagleBone AI-64 utilizes TIDL to run deep learning inference efficiently. TIDL enables the BeagleBone AI-64 to convert, optimize, and execute deep learning models from frameworks like TensorFlow and ONNX, making full use of the processor’s AI accelerators and DSPs for high-performance and low-power inference. This integration allows developers to deploy AI applications on the BeagleBone AI-64, taking advantage of TIDL’s capabilities to run models optimized for the board’s hardware.
Accelerated inferencing
In order to do accelerated inferencing on BeagleBone AI-64 there are 3 steps:
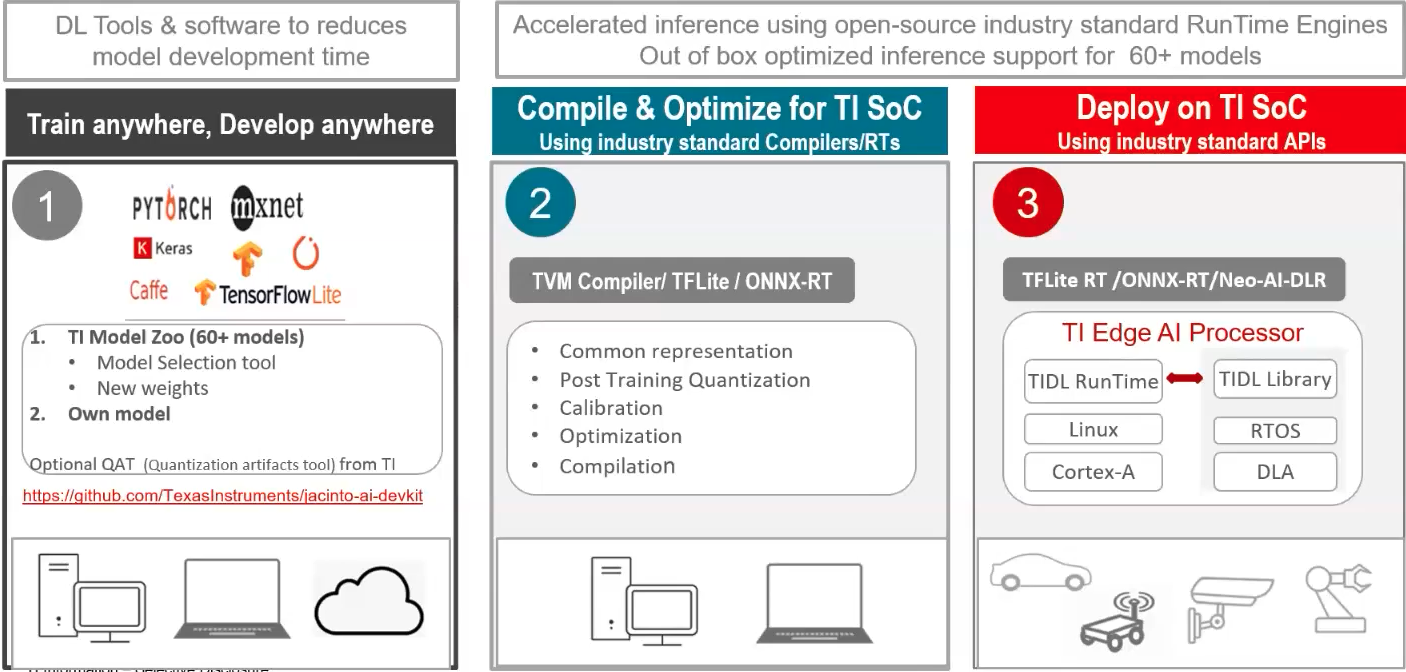
Step1-Train and Develop
By the end of Week 5, I had the CNNs model ready. But, there is something which needs to be done before converting the model into tflite. It is to fix the batch size of the model to 1. I figured this out later when I encountered errors during the compilation of model(Step2).
So what does this fixing of batch size to 1 means. The output of cnn_model.get_config() before fixing the batch size to 1.
{'name': 'sequential',
'layers': [{'module': 'keras.layers',
'class_name': 'InputLayer',
'config': {'batch_input_shape': (None, 150, 1152),
'dtype': 'float32',
'sparse': False,
.
.
.
.
We can see how the batch_input_shape is (None, 150, 1152). This means the input can contain any number of samples. But, doing this will raise an error RuntimeError: Attempting to use a delegate that only supports static-sized tensors with a graph that has dynamic-sized tensors.
So, we need to fix the input shape:
config = cnn_model.get_config()
for layer in config['layers']:
if 'batch_input_shape' in layer['config']:
shape = layer['config']['batch_input_shape']
shape = (1, *shape[1:])
layer['config']['batch_input_shape'] = shape
Now, we need to create a new model from the updated config:
cnn_model_new = cnn_model.from_config(config)
cnn_model_new.set_weights(cnn_model.get_weights())
cnn_model_new.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
The output of the cnn model after fixing the batch size to 1 cnn_model_new.get_config()
{'name': 'sequential',
'layers': [{'module': 'keras.layers',
'class_name': 'InputLayer',
'config': {'batch_input_shape': (1, 150, 1152),
'dtype': 'float32',
'sparse': False,
.
.
.
.
From the ‘batch_input_shape’: (1, 150, 1152) it is clear that the batch size is fixed. Now, we can convert the cnn model into tflite model.
converter = tf.lite.TFLiteConverter.from_keras_model(cnn_model_new)
converter.experimental_new_converter = True
tflite_model = converter.convert()
# Save the converted model
with open('cnn_model.tflite', 'wb') as f:
f.write(tflite_model)
I will discuss the next steps of model compilation and model inferencing in the next blog.
So, Stay tuned!
Thanks for reading the blog.
Happy Coding!!