Intro
Machine learning models rely heavily on the quality and quantity of training data. For projects like “Enhanced Media Experience with AI-Powered Commercial Detection and Replacement,” obtaining comprehensive datasets is crucial. However, acquiring large-scale video datasets, particularly for commercial and non-commercial content, presents challenges due to their size and storage requirements.
YouTube-8M Dataset
The YouTube-8M dataset stands out as a significant resource for this project. It includes millions of YouTube video IDs with detailed machine-generated annotations across a diverse set of visual entities, including "Television Advertisement," which is particularly relevant here.
Dataset Structure
The actual structure of how the data is stored is in compressed protobuf files that are using the TensorFlow version of these types of file structures in tensorflow.Example and tensorflow.SequenceExample. Each video is stored in one of these types of objects and then grouped into TFRecords.
Compression was needed to make it easier to develop a model because the raw dataset is hundreds of terabytes considering the original 8 million is over 500K hours of video. For the frame-level features, the entire video frame image (one per second with up to the first 360 seconds per video) was pre-processed with the publicly available Inception network that was originally trained on ImageNet. This reduced dimensionality to 2048 features per frame and pulled motion out of the video in essence making it a still video. Research has show motion features have diminishing returns as the size and diversity of the video data increases. PCA with whitening was also applied to reduce to 1024 features per frame. Finally, the data was compressed from 32-bit to 8-bit data types. More information can be found in the paper YT-8m: A Large-Scale Video Classification Benchmark.
Tensorflow.SequenceExample
The tensorflow.Example structure is a compact data format that uses a key-value store where each key is a string mapping to a value, which can be a list of bytes, floats, or int64s. This standardized open data format is flexible, allowing users to define keys and their corresponding values. It essentially serves as TensorFlow’s implementation of protocol buffers (protobuf), facilitating the storage and sharing of unstructured data, such as visuals.
On the other hand, the tensorflow.SequenceExample is designed to handle one or more sequences along with context that applies to the entire example. The primary distinction between the two is that SequenceExample includes a FeatureList, which represents the values of a feature over time, or across frames.
TFRecord
TFRecord is a simple format that stores binary records or another way to say it is it’s a datatype created by the TensorFlow project to serialize data and enable reading it linearly. The .tfrecord files store a couple hundred tensorflow.Example or tensorflow.SequenceExample objects that are 100–200MB each.
Feature Types
There are 2 versions of the features: frame-level and video-level. Video-level features are features like audio and rgb features averaged per video which is fewer than specific audio and rgb features per frame.
But, we are interested in the frame-level features.
The Frame level dataset is stored as tensorflow.SequenceExample object and grouped into a total of 3,844 TFRecords. Each record holds around 287 videos.
The total size is around 1.53TB (estimated about 1.1M videos) and has the following structure:
- id: unique YouTube video id. Train includes unique actual values and test/validation are anonymized
- labels: list of labels for that video
- rgb: list of 1024 8 bit quantized frame rgb features for that video
- audio: list of 128 8 bit quantized frame audio features for that video
Example of Frame-level features dataset
Frame-level features are stored as tensorflow.SequenceExample protocol buffers. A tensorflow.SequenceExample proto is reproduced here in text format:
context: {
feature: {
key : "id"
value: {
bytes_list: {
value: (Video id)
}
}
}
feature: {
key : "labels"
value: {
int64_list: {
value: [1, 522, 11, 172] # label list
}
}
}
}
feature_lists: {
feature_list: {
key : "rgb"
value: {
feature: {
bytes_list: {
value: [1024 8bit quantized features]
}
}
feature: {
bytes_list: {
value: [1024 8bit quantized features]
}
}
... # Repeated for every second, up to 300
}
feature_list: {
key : "audio"
value: {
feature: {
bytes_list: {
value: [128 8bit quantized features]
}
}
feature: {
bytes_list: {
value: [128 8bit quantized features]
}
}
}
... # Repeated for every second, up to 300
}
}
Vocabulary
The vocabulary.csv is a data dictionary for the label ids mapped to label names and other relevant details for the video classifications. Basically, all the actual labels in the data examples and model predicted outputs are numbers and this is your decoder ring for what those numbers mean.
Our Television Advertisement entity maps to 315 label_id using this vocabulary.csv.
Implementation
To manage the dataset’s scale (approximately 1.53TB and 1.1 million videos), I processed one-tenth of the dataset at a time. Each TFRecord file, containing around 287 videos.
Each TFRecord inside TFRecord file is processed as shown:
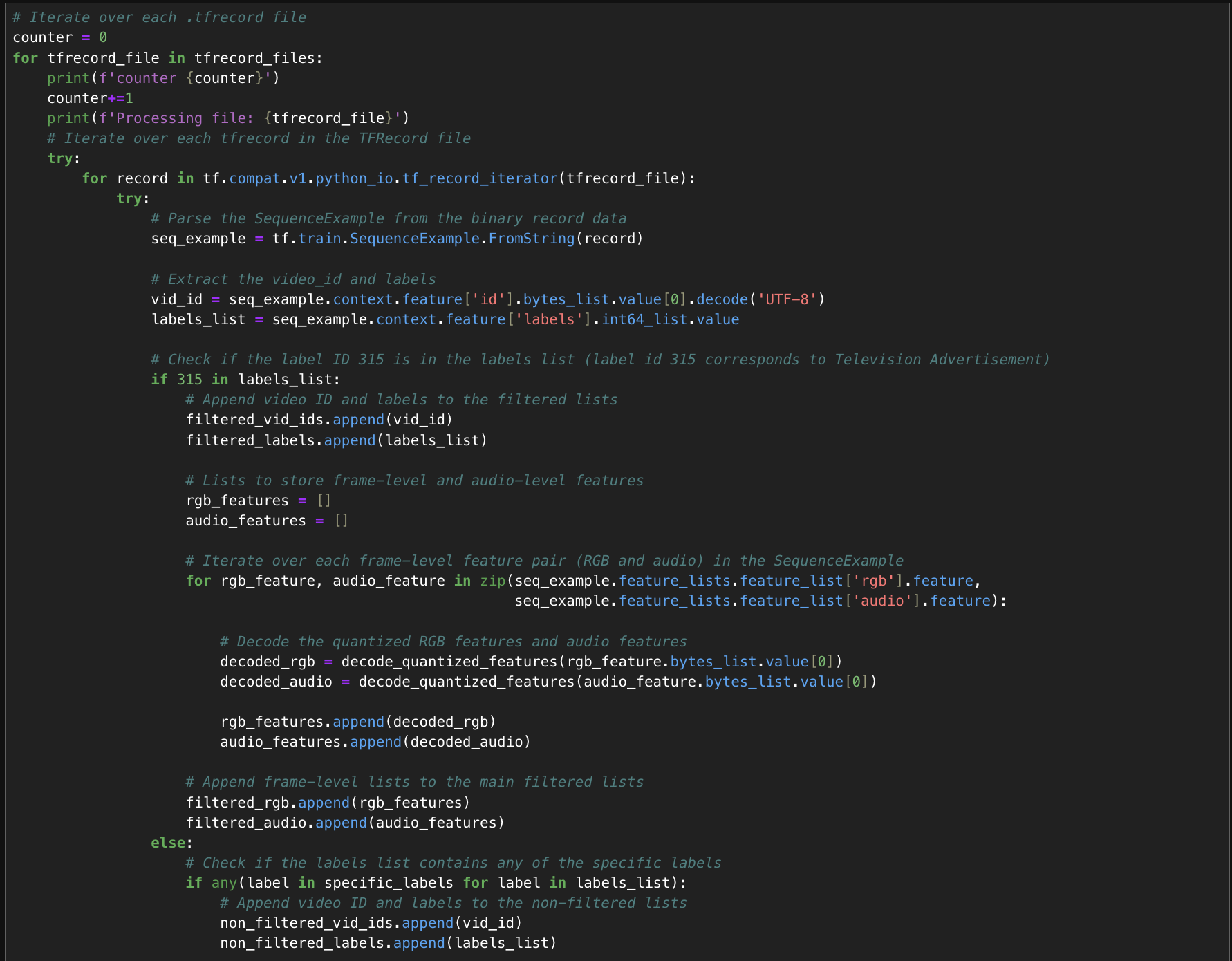
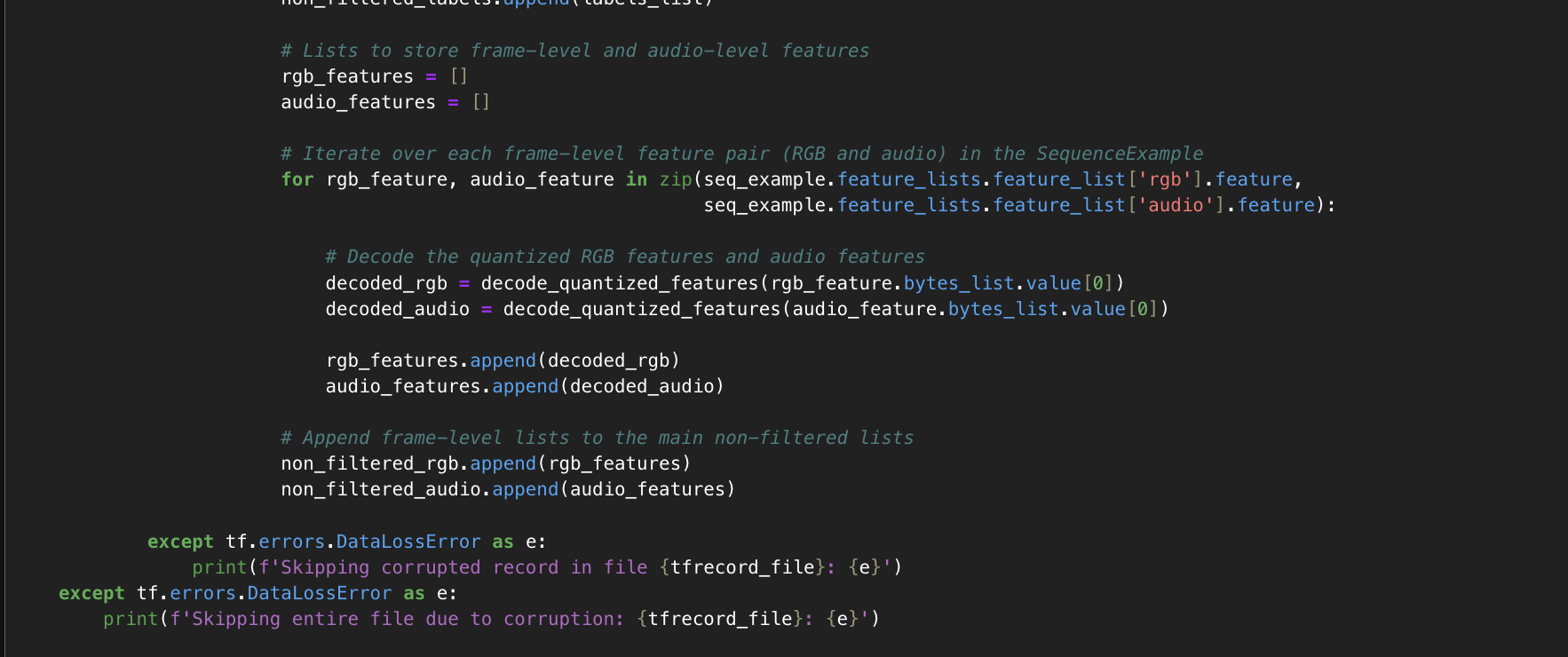
At this point, the following lists contain the relevant data:
- filtered_vid_ids, filtered_labels, filtered_rgb, and filtered_audio contain data for videos with the label “Television advertisement”.
- And, the non_filtered_vid_ids, non_filtered_labels, non_filtered_rgb, and non_filtered_audio contain Non-Commercial Videos data.
Non-Commercial features
Additionally, I considered specific non-commercial entities like sports, entertainment, and other genres to ensure a balanced dataset. These include:
- Football(Label_id - 12)
- Wrestling(Label_id - 329)
- Zee TV Drama(Label_id - 653)
- Harry Potter(Label_id - 282)
- Basketball(Label_id - 52)
- Dog(Label_id - 67)
- Boxing(Label_id - 92)
- Hockey(Label_id - 118)
I randomly choose ~450 features out of all non-commercial entites features in every iteration to maintain balance in the dataset.
Conclusion
The collected dataset will play a crucial role in training the model. The next task is to merge the audio and visual features for each video and proceed with developing the model pipeline.
Links
- Dataset Collection And Feature Extraction Codes Link